
This is Part 2 of our 6-part Deep Dive series on neuromorphic computing—the brain-inspired processors achieving 1,000× efficiency improvements over GPUs at the edge.
[🧠] Sapien Fusion Deep Dive Series | February 4, 2026 | Reading time: 5 minutes
Intel Loihi 3
Intel’s neuromorphic journey began in 2017 with Loihi 1, continued through Loihi 2’s 2021 release, and culminates in Loihi 3’s January 2026 commercial availability, a processor that represents the most significant architectural departure from conventional computing since GPUs themselves emerged. This isn’t an incremental improvement. This is brain-inspired computing that finally delivers on decades-old promises.
The Architecture
Loihi 3 packs 8 million digital neurons and 64 billion synapses onto a single 4nm die—an eightfold density increase over its predecessor. But raw neuron count misses what makes this architecture transformative.
Traditional processors, CPUs, GPUs, and even specialized AI accelerators operate synchronously. Every clock cycle, every processing element performs computation regardless of whether new information arrived. Neuromorphic processors operate asynchronously, activating only when events occur.
Think of conventional processors as security guards checking every door in a building every second, whether threats exist or not. Neuromorphic processors are motion sensors that only activate when something actually moves. The energy savings compound dramatically when most sensory input remains static or changes slowly—exactly what characterizes real-world edge environments.
Graded Spikes: Bridging Two Worlds
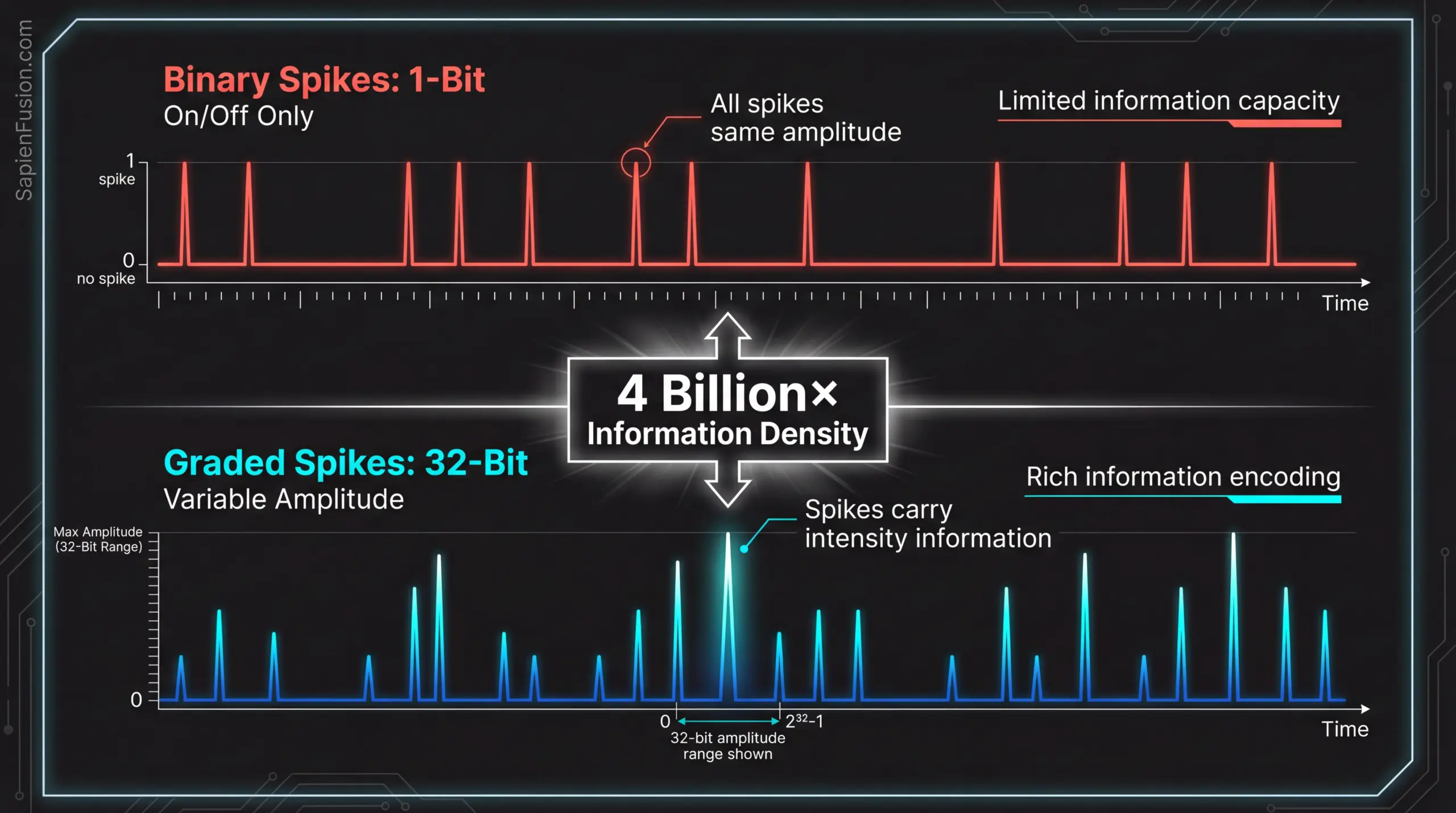
Loihi 3’s critical innovation introduces 32-bit graded spikes—a bridge between traditional deep neural networks operating on continuous values and spiking neural networks communicating through discrete events.
Earlier neuromorphic generations used binary on/off signaling. A neuron either fired or didn’t. This forced algorithms designed for conventional architectures to undergo complete rewriting. Converting a PyTorch model to a binary spiking neural network required redesigning activation functions, adjusting learning algorithms, tuning temporal dynamics, and accepting accuracy degradation. The result created high barriers to adoption, and most developers stayed with GPUs.
Graded spikes solve this problem by encoding information into spike amplitudes across a 32-bit range. Each spike carries nuanced information—not just fire or don’t fire, but fire with this specific intensity. This enables mainstream AI workloads to run on neuromorphic hardware with dramatically reduced power while requiring minimal algorithmic adaptation. Developers can convert existing models with automated tools currently in development, maintain accuracy within 1-2% of original performance, and achieve neuromorphic efficiency without complete redesign. This technical bridge makes commercial viability possible.
Event-Driven Computation at Scale
The power efficiency advantage comes from temporal sparsity—the principle that most neurons remain inactive most of the time, processing only when relevant events occur.
GPU processing a video stream at 30 frames per second processes all pixels with full computation for every frame, regardless of whether the scene changes. Frame 2 might be 95% identical to Frame 1, but the GPU performs full computation anyway. Frame 3 might be 97% identical to Frame 2, but again receives full computation. The result delivers massive redundant processing, consuming constant power.
Loihi 3 processing the same video stream activates neurons to establish a baseline during the initial scene, then only fires 5% of neurons to detect the changes in Frame 2 when 95% remains unchanged. Frame 3 triggers only 3% of neurons, when 97% stays static. Power consumption becomes proportional to actual information content rather than frame rate.
For event-driven sensory data from neuromorphic cameras and event-based audio, Loihi 3 achieves theoretical 1,000× efficiency versus GPUs. This isn’t marketing hyperbole—it’s architectural mathematics. Temporal sparsity with 99% of neurons inactive delivers a 100× reduction. Spatial sparsity through local processing without global synchronization provides a 10× reduction. Combined, these factors multiply to 1,000× efficiency. Real-world performance varies by workload, but event-based applications routinely achieve 500-1,000× improvements.

On-Chip Learning: STDP
Spike-Timing-Dependent Plasticity enables Loihi 3 to adapt and learn on-device without cloud connectivity or model redistribution. When two connected neurons fire in close temporal proximity, the system strengthens the connection if neuron A fires immediately before neuron B, indicating A likely causes B. The system weakens the connection if neuron A fires after neuron B, showing that A doesn’t cause B. This local learning rule requires no global coordination, no backpropagation, no centralized training—just temporal correlation detection.
When a quadrupedal robot encounters unexpected terrain, its gait pattern may cause stumbling—a negative outcome. STDP weakens neural connections, producing that gait. Alternative connections strengthen through exploration. The robot adapts its gait for new terrain automatically. No data transmission occurs. No cloud processing happens. No firmware update deploys. The intelligence adapts locally and continuously.
Industrial environments change constantly. Equipment configurations shift. Payload weights vary. Environmental conditions fluctuate. Traditional AI requires collecting new data representing changed conditions, retraining models in centralized systems, validating updated models, deploying to edge devices, and monitoring for degradation. This timeline spans days to weeks per adaptation cycle. Loihi 3 with STDP enables continuous adaptation in milliseconds to seconds. The system learns as it operates.
Hala Point: Proving Scalability
Intel’s Hala Point system, deployed at Sandia National Laboratories, packages 1,152 Loihi 2 processors—the same architecture family as Loihi 3—into a rack-scale neuromorphic supercomputer. The system contains 1.15 billion neurons, achieves 15+ trillion operations per second per watt, consumes 2,600 watts peak power, and delivers standard AI benchmark performance matching GPUs. For comparison, GPU systems delivering equivalent throughput consume 8,000-12,000 watts.
Hala Point proves neuromorphic architecture scales to billion-neuron systems, delivers performance competitive with GPUs on standard benchmarks, achieves 3-5× better efficiency than GPUs even on non-event-driven workloads, and operates production-ready in national laboratory environments for real research. The skepticism that neuromorphic computing doesn’t scale or only works in labs ended when Hala Point went operational.

Commercial Availability and Real-World Performance
Intel’s Neuromorphic Research Community provides access to Loihi 3 hardware through a membership program. Organizations join INRC to receive Loihi 3 development boards, access the Lava software framework, collaborate with the research community, and develop proprietary applications. As of January 2026, limited commercial availability expands with growing production capacity throughout 2026, targeting broader commercial release in Q3-Q4 2026. Automotive partnerships already receive production allocation.
Recent deployments demonstrate Loihi 3’s practical advantages. The ANYmal D Neuro quadruped operates 72 hours continuously compared to 8 hours for GPU versions, maintains autonomous navigation at 2 meters per second, performs real-time obstacle avoidance, and processes everything on board without cloud requirements. Mercedes-Benz vision systems achieve 0.1 millisecond pedestrian detection latency versus 30-50 milliseconds for GPUs, reduce processing power by 90%, and target production integration for 2027-2028. Industrial inspection robots demonstrate extended deployment ranges with ninefold battery improvements, reduced charging infrastructure requirements, and lower total cost of ownership.
The Software Challenge
Hardware capabilities exceed software ecosystem maturity. Intel’s Lava framework provides cross-platform abstraction across CPU, GPU, and Loihi hardware, uses a Python-based development environment, offers a growing algorithm library, and benefits from open-source community contributions. Current limitations include steep learning curves for developers trained on PyTorch and TensorFlow, limited conversion tools still in development, fragmented ecosystems across neuromorphic vendors, and relatively small developer communities.
Industry consensus projects 2-3 years for automated model conversion tools, comprehensive algorithm libraries, standardized APIs across platforms, and mainstream developer adoption. Organizations investing now in neuromorphic expertise establish a competitive advantage before ecosystem maturity enables widespread adoption.
Strategic Positioning
Loihi 3 benefits battery-powered autonomous systems, including industrial, service, and exploration robotics, inspection and monitoring drones, prosthetics and health monitor wearables, and wildlife tracking and environmental monitoring IoT sensors. Real-time processing requirements span autonomous vehicle collision avoidance, industrial automation safety systems, medical device closed-loop control, and defense system threat detection. Edge deployment constraints include remote locations without power infrastructure, harsh environments with limited cooling, privacy-critical applications requiring local processing, and bandwidth-limited scenarios with intermittent connectivity.
Organizations beginning Loihi 3 evaluation now follow a timeline of prototype development and validation in 2026, production integration and testing in 2027, and commercial deployment at scale in 2028. Organizations waiting for mature ecosystems begin evaluation in 2027-2028 as tools mature, prototype development in 2028-2029, and production deployment in 2029-2030. The first-mover advantage spans 2-3 years of market positioning before followers deploy.
The Efficiency Revolution
Loihi 3 represents the culmination of 15+ years of neuromorphic research, achieving commercial viability. The 1,000× efficiency improvements aren’t theoretical—they’re demonstrated in production deployments, enabling applicationsthat GPU architectures fundamentally cannot serve. The question for technology strategists becomes whether your organization needs the capabilities neuromorphic computing enables. If battery life, latency, or edge deployment constraints matter, the answer determines competitive positioning through 2030.